









Quality recommendations in e-commerce – components of basic algorithms








In the first article of the series, we talked about the properties of quality recommendation algorithms that are necessary for practical use of the algorithm. In the second article, we considered the components of the Related Products algorithm. But the recommendation system for an online store consists not only of the “Related Products” algorithm. There are other equally important algorithms.
In the final article of the series, we’ll look at a few algorithms and break down some of their components that are most important and different from the ones we looked at earlier.
Recall that we call a component a part of an algorithm that is responsible for a certain functionality and can provide one or more properties. Components that solve similar problems for different algorithms may be different. This is because different algorithms help solve different buyer problems. For example, the “Cold Start” component for the “Related Products” and “Alternatives” algorithms must find products that match each of these algorithms. For “Related Products” – products that complement the purchase well, and for “Alternatives” – options that can be considered instead of the current product.
As in the last article, for each component we will tell you:
- what problem the component is needed to solve;
- how we solve the problem in our algorithm;
- how to determine if there is a problem in the recommendation system;
- what properties the component provides.
The Alternative Goods algorithm and its components.
The algorithm shows goods that may be more suitable for customers. It helps the doubters to make a choice. When a shopper considers an item, the algorithm suggests other options that may suit them better, which can lead to a purchase. This is one of the most commonly used algorithms on a product card page.
Leveraging customer behavior.
The first thing you want to use as alternatives are products that have similar descriptions and attributes. The problem is that the most similar products are not necessarily the best alternative. For example, if a customer is looking at a TV and has gone into a store to look at different options, they may find a TV that they are interested in, but doesn’t fit the diagonal size. In this case, alternatives may offer other televisions, but with a different diagonal size more suitable for him, which are often bought by people who were interested in the original product.
Let’s take another example, when similarity in description does not allow you to show the most appropriate products. Let’s say that during Black Friday there was a promotion for a refrigerator, and it was bought more often. This product did not become more similar to the refrigerator the user is interested in, but it became a better alternative for him. A similar situation occurs when the promotion is over and the product is no longer in demand and is no longer the best alternative.
We have developed an algorithm that learns from the behavior of all shoppers and shows in recommendations the products that are most likely to be added to the cart and purchased after viewing the current product. If the data on cart additions and orders is insufficient, the algorithm uses data on product views of all users. And only if such data is insufficient, information on similarity of description and attributes is used.

To test the work of the component, you need to find a block with recommendations of alternative products on the page of a popular product. Recommendations should offer products that are similar in description to the product being viewed, as well as those that are not similar to it, but can be a good alternative to it.
The component provides the following properties:
- efficiency – the most appropriate alternatives can be found;
- context awareness – the behavior related to the current product is taken into account;
- relevance – recommendations change with changing customer behavior.
Addressing the problem of cold starts.
If you base alternative recommendations solely on customer behavior data, you may not be able to generate recommendations for all products when there is insufficient data for some of them. This is most often the case for unpopular and new products. In the previous article we discussed this problem, but we decided to mention it here as well, since different algorithms may have different components designed to solve the same problem.
As a solution, we implemented a component that finds suitable products using similarity of attributes. This makes it possible to show recommendations for almost all products. Products that have enough behavioral data will be shown first.
To test the component, you can visit the cards of new or unpopular products and make sure that the recommendations are displayed. In addition, you should make sure that the products from the recommendations are alternative to the current product.
The component provides the following properties:
- coverage – recommendations are generated for products without sufficient data on customer behavior.
The “Popular Products” algorithm and its components.
When a customer enters an online store, the first thing to do is to interest him. To do this, he can be shown the best offers in the store. In addition, the buyer needs to understand as early as possible what types of products are present in the assortment of the store. These tasks are solved with the help of the “Popular Products” algorithm. The algorithm is most useful on the main page of the site, in child and parent categories, but it can also be shown on other pages.
Increase the variety of products in recommendations.
The most popular products in a store can be very similar. For example, in an electronics store, popular products may be smartphones, which will occupy a large number of positions in the recommendations block. Since the number of products to be shown in the recommendations block is limited, there will be no room for products that could give a better idea of the store’s assortment.
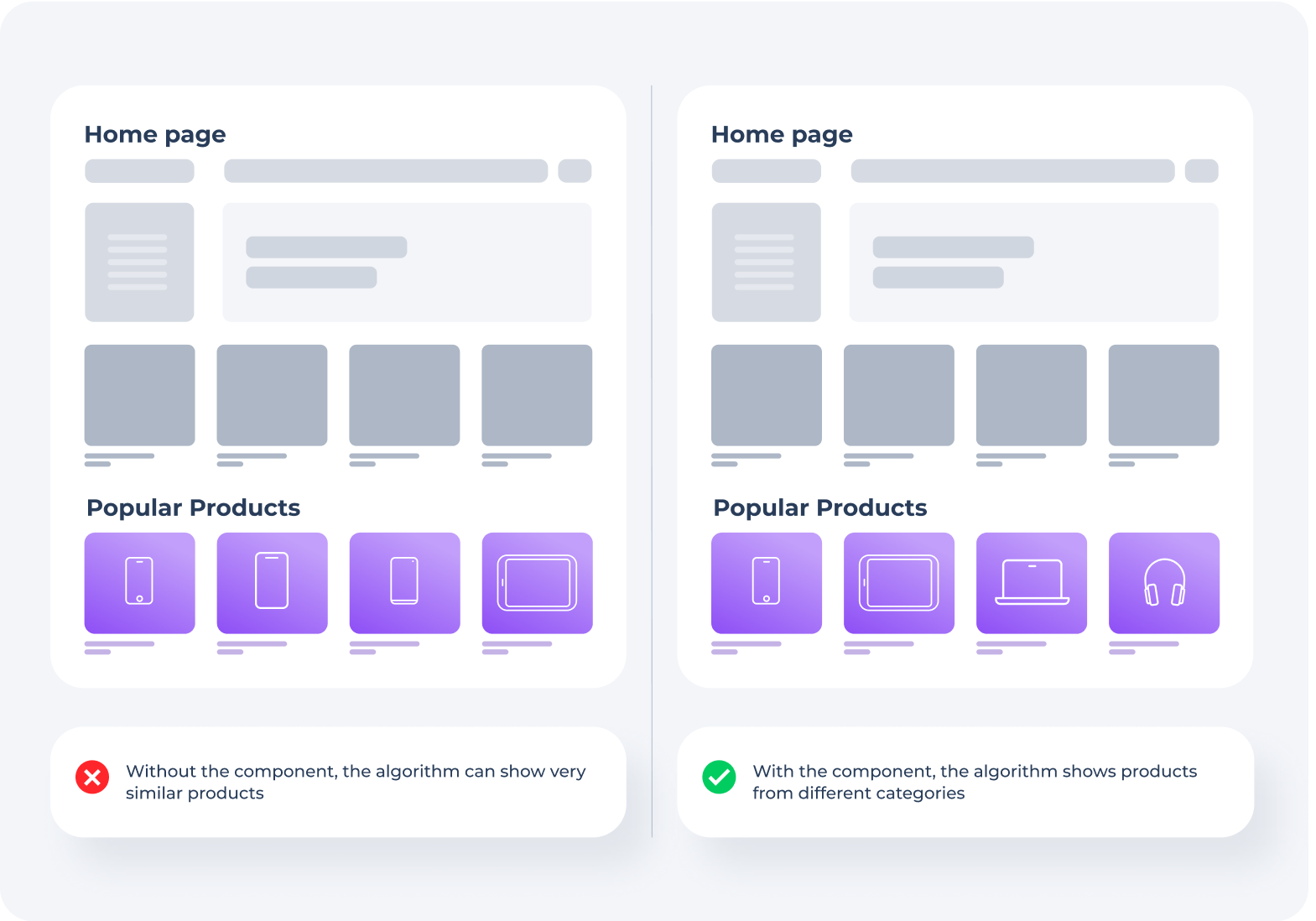
To solve this problem, Retail Rocket Group shows goods from the largest number of different categories in the algorithm. The most popular products are selected for each category. For example, if there are more than 5 categories in the store, and there are 5 positions in the recommendation block, one most popular product from the 5 most popular categories will always be shown.
It is not difficult to check the work of the component. It is enough to visit the main page of the store and make sure that the block with popular products does not show a lot of similar products.
The component provides the following properties:
- efficiency – recommendations give a better idea of the store’s assortment;
- coverage – more products from different categories are shown.
Using category hierarchy.
In the popular products recommendations on the parent category page, you need to show the products of its child categories. For example, to show popular products for the electronics category, you need to know all of its child categories. The electronics category itself may not have any products, and if you ignore the child categories, there will be no products in the recommendations.
Our system uses category hierarchy data provided by the online store to calculate the algorithm. Thus, the recommendations for parent categories show products from child categories.
The component provides the following properties:
- scope – recommendations for parent categories are generated.
Increasing the impact of up-to-date data.
Interest in products may change over time and they may become less or more popular. This can be influenced by various external factors such as seasonality, promotions, etc. For example, during the summer season, customers often ordered shorts, which became very popular in the store. And it may happen that when the winter season arrives, no other warmer product gains the same popularity, which means there is a risk that shorts may show up in recommendations in the wrong season.
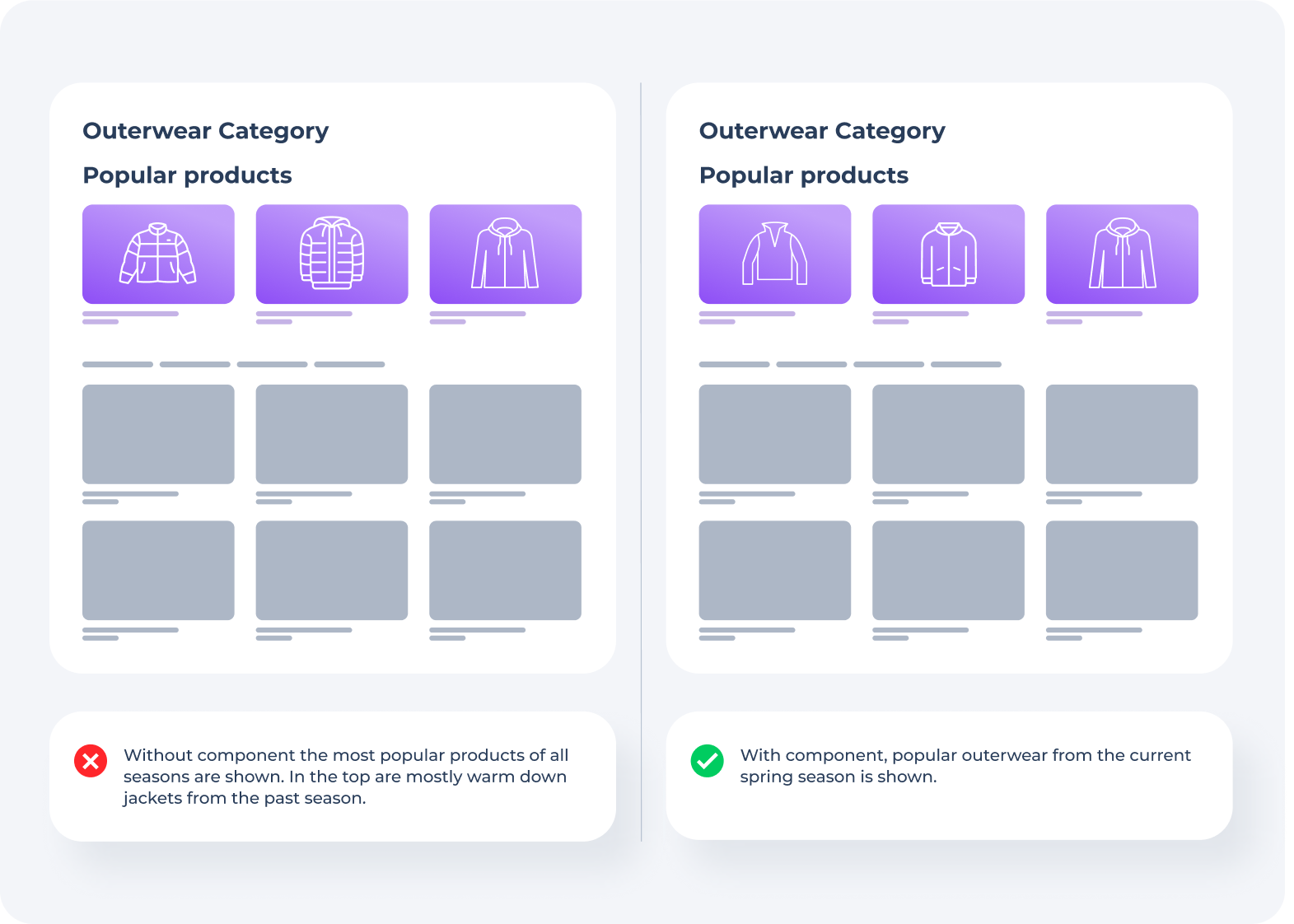
In our algorithm, the newer the data, the more influence it has on recommendations. At the same time, the older the data is, the slower its influence on recommendations decreases. For example, data that entered the system today and a month ago have a different impact on recommendations. And data that came in a year ago and a year and a half ago have about the same impact.
Our system takes into account all available data from the entire history. Old data has less influence, but it also takes part in the calculation of recommendations, just like new data. To get the most relevant recommendations for the current moment, we could take only the recent history, but then the coverage for categories with products that are not popular at the current moment would suffer.
To check it, just look at categories with products from different seasons and make sure that popular recommendations correspond to the current season. Categories with unpopular items from the current season should also show recommendations.
The component provides the following properties:
- relevance – recommendations show products that match the current buying behavior.
Using different types of events.
Customers perform various actions on a store’s website: ordering, adding to cart, clicking on recommendations, and browsing products. The most important action is orders, but they tend to be relatively few in number. On the other hand, a customer may be interested in a product but not buy it, which can be an important signal to the algorithm. Thus, it is necessary to consider different types of interactions and balance their impact on the algorithm.
In our algorithm, all interactions with a product are taken into account, and each of them has a different impact on the popularity of the product. For example, a product that has been bought 10 times will be more popular than a product that has been viewed 100 times. But if the second product is viewed much more often, it will at some point become more popular than the first. Different types of interactions also lose their influence over time in different ways. We have experimentally determined the optimal balance between the influence of different types of interactions on the popularity of goods.
It is difficult to visually check the work of the component, but sometimes you can use categories with cheap and expensive goods for this purpose. Cheap products are more likely to be bought, so they should show up more often in the popular ones. For example, in the popular recommendations for the TV category, there should not be an overly expensive TV that is very rarely bought.
The component provides the following features:
- coverage – more data about different types of interactions is used, as a consequence, more categories will have enough recommendations.
Filtering out anomalies in the data.
Even a single customer can take too many actions with individual products and affect their popularity. Then, products that are not really popular may appear in recommendations. In addition, the popularity of products can be arbitrarily influenced by search and other robots.
In our algorithm, we have limited the impact on popularity for each individual customer over a small period of time. We measure popularity not by how many interactions there have been with an item, but by how many shoppers have interacted with the item over time. We filter traffic from bots completely.
If, despite the correct operation of all other components, you observe illogical products in recommendations, then as a result of a detailed investigation of the problem, you are likely to find an anomaly in the data.
The component provides the following properties:
- coherence – data that distorts recommendations are filtered out.
The Personal Interest in Categories algorithm and its components.
The algorithm identifies categories that are interesting to the buyer in the long term. For these categories, it can show different products such as popular, new or other products. This is one of the personalization algorithms, and we will use its example to demonstrate important features related to personalization in general. The algorithm is most commonly used on the homepage and on the parent category page.
The influence of categories on interest formation.
Depending on the category with which a shopper interacts, interests can be shaped in different ways. For example, after buying diapers or pet food, a person will develop a long-term interest in these categories. And after buying a smartphone or a refrigerator, a person will not form an interest in the category, as it is unlikely that he or she will need a second product of the same category soon.
Our algorithm for each category understands how a shopper’s interest should change after an interaction. Each type of interaction can have a different impact on a customer’s interest in a category. For some categories, viewing the category page creates the most interest, for others – viewing a card, ordering or adding a product from that category to the cart. However, it often happens that not all categories have enough data for the system to understand how to generate interest. Therefore, we collect data for all similar categories of the store and use it to determine how interest is formed.
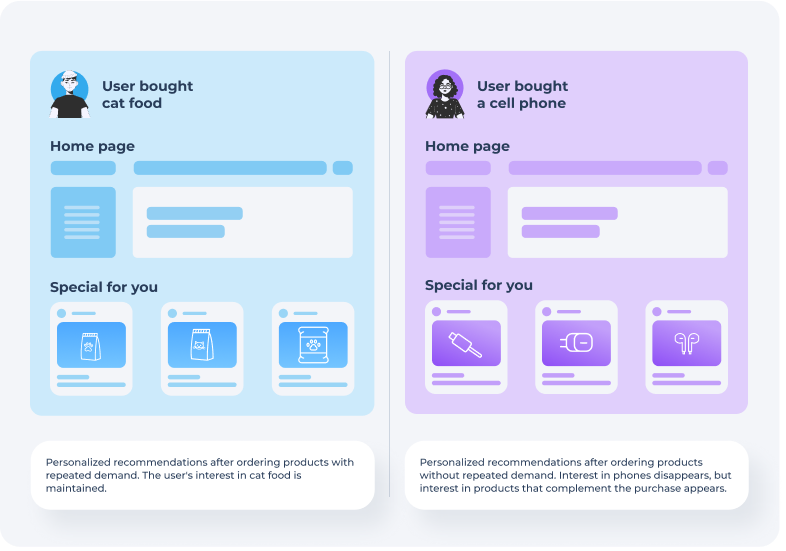
You can check the work of the component by placing an order for a product that does not have a repeated demand and make sure that products from the same category have disappeared from the personal recommendations.
The component provides the following properties:
- context awareness – buyer and category context is used;
- efficiency – the recommendations correspond to the buyer’s task.
Generating interest in related categories.
As we wrote earlier, interest in some categories may disappear after ordering. In such a case, it is not obvious what can be shown in personalized recommendations to buyers. At the same time, the buyer may benefit from products that complement his order. For example, if a product from the category of phones was bought, for which there is no repeated demand, it makes no sense to show other phones in personal recommendations, but it is possible to show products that complete the order.
In our system after an order can be formed interests to the categories, the goods from which complement the previously made order. For example, after buying a phone you can show recommendations from such categories as: cases, protective glasses and other accessories. In other words, the algorithm can suggest related products to the previously purchased ones. Note that it does not make sense to generate interest in related categories for every category.
You can verify the work of the component by placing an order for a product that does not have a repeated demand and making sure that the personalized recommendations include products that complement the previously purchased product.
The component provides the following properties:
- efficiency – helps the customer find products that complement the order;
- coverage – generates interest in more categories.
Real-time calculation of personalized recommendations.
If a customer has taken an action and their interests change, the recommendations should change immediately. For example, if a customer was not interested in a product before, but now shows interest in it, then similar products should appear in the recommendations immediately. Otherwise, the recommendations will not help the buyer solve his current problem.
To solve the problem, our system obtains behavioral data and changes the buyers’ interest in categories in real time. An additional complexity is created by the fact that the system needs to store interaction data for each user over time. This is necessary because personalization needs to account not only for actions in the current session, but also in past sessions when a person leaves for a long time, comes back and continues with a past task.
In addition to the interests themselves, the system calculates in advance the rules by which they change. It is impractical to perform such a calculation in real time, since all available data about the behavior of all visitors to the store are used, and the calculation turns out to be computationally very complex. In addition, these rules change slowly over time, so they do not need to be updated immediately.
To check the work of the component, you just need to look at some products in the store and make sure that similar products appear in the block with personal recommendations.
The component provides the following properties:
- efficiency – recommendations correspond to the current task of the buyer;
- relevance – recommendations are changed in a timely manner.
The “Accessories” algorithm and its components.
The algorithm helps the buyer to choose accessories that complement the product.
For example, if the buyer has chosen a smartphone, the algorithm will immediately offer him a suitable case, headphones, protective glass, etc. The main difference between accessories and related products is that related products can be used without each other, for example, pants and sneakers, while accessories are used only together with the main product.
Automatic detection of categories with accessories.
The algorithm needs to know not only which items are complementary to the current item, but also which items are accessories. It is possible to manually select store categories whose items are accessories. But this requires human resources, and constantly, since the categories on the site change, and, as a consequence, it is necessary to define new categories with accessories. In addition, with a large number of actions, a person can make mistakes.
Our system, without the involvement of a marketer, automatically detects accessory categories and is able to show accessories that fit the current product.
The component provides the following properties:
- efficiency – the algorithm helps the buyer to better solve the task of searching for accessories;
- relevance – recommendations automatically take into account the appearance of new accessories;
- coverage – recommendations take into account more accessory categories and, as a result, recommendations can be shown to more products.
The Upsell algorithm and its components.
The algorithm recommends products that are as similar as possible, but with improved characteristics and more expensive. For example, if a buyer is looking at wired headphones for 2000 rubles and is going to order them, the algorithm will show the buyer very similar but wireless headphones for 3000 rubles, which will suit him no less than the wired ones. The buyer can compare them, consider that the wireless headphones will be more comfortable, and buy the more expensive version.
At the same time, the recommendations of this algorithm may differ significantly from those in the previously discussed Alternatives algorithm.

Using the popularity of products.
The algorithm can find many suitable goods from which the best ones should be selected to be shown in the recommendations. In this case, we cannot, as in alternatives, use the preferences of other shoppers who were interested in the given product, because in such a case goods that do not fit the task of the Upsell algorithm may be shown.
To select the best items, we first show the more popular items that are most often preferred by the store’s customers. For example, if a customer is looking at clothes, and the style is a determining criterion for him or her as to whether the clothes fit him or her, the algorithm can find clothes of the same style but with better materials. And this component will help to select the items that the user is most likely to like from the already found items.
To check, you need to go to the popular product card and make sure that the products that are shown by the algorithm should be popular in the current product category.
The component provides the following properties:
- efficiency – recommendations show with the highest probability suitable goods.
Conclusion
There are other recommendation algorithms in our system that contain many other components. In different algorithms, the components may solve similar tasks and work in a similar way, but each of them has its own specifics. In this article we have considered the most interesting components, the need for which may not be obvious at first glance.
In the series of articles, we have identified the properties required for quality recommendations and shown that without these properties, buyer and business objectives will not be met. Providing a single property is usually not very difficult, but implementing recommendations that have all properties simultaneously becomes a challenge.
Successfully accomplishing this task requires components that are capable of providing one or more properties while not interfering with the provision of the others. At the same time, each recommendation algorithm has its own peculiarities, which leads to a unique set of components. All this makes the development of a recommendation system very expensive.
We hope that if you are faced with the task of developing a recommendation system, this series will help you understand what you need to do to make the system usable. And if you need to select a recommender system, the series will provide you with a way to assess its quality.