









Quality recommendations in e-commerce – components of the Related Products algorithm








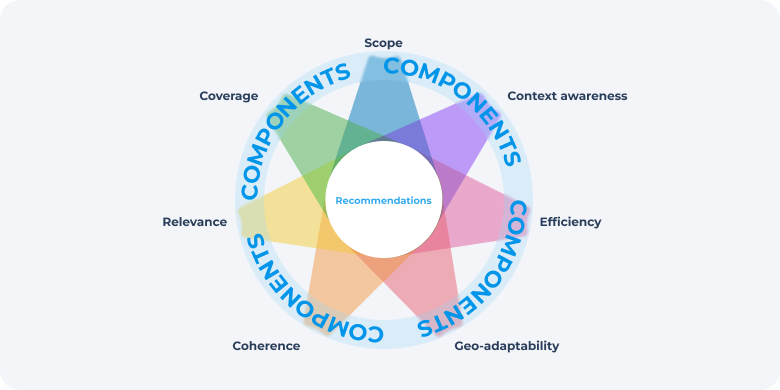
In this post, we describe how to provide these properties using the example of components of one of the algorithms.Recommendation algorithms can be divided into components, each of which is responsible for providing one or more properties. For example, one component may provide personalization, another may provide logical recommendations for new products. We chose the related goods algorithm for the paper because it consists of many different components.
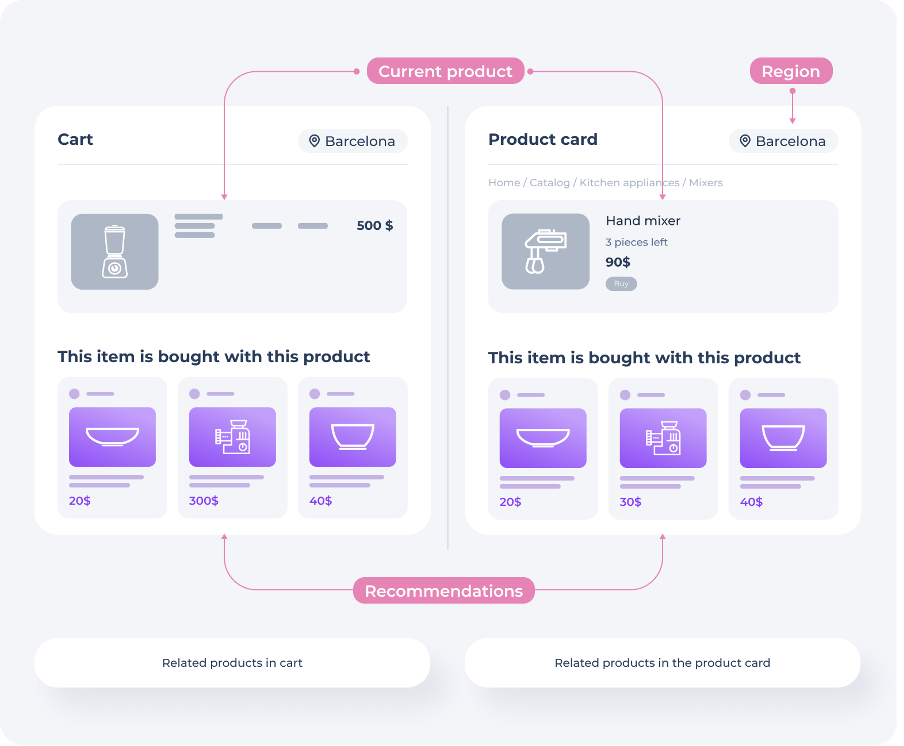
Related products are items that a customer can add to their order. We at Retail Rocket Group widely use this algorithm on many online stores in various segments. As a rule, it is used on the cart and product card pages.
Over the last 10 years, we have been actively working on improving our algorithm, and during this time it has undergone significant changes. These changes have been made to ensure that all necessary properties are achieved. To make sure that each change in the algorithm accomplishes its goals, we have conducted many experiments. We will provide details about our hypothesis testing process in a separate article.
Let us remind you what properties need to be ensured for high-quality recommendations:
| Property | Description |
| Task-Oriented Effectiveness | Recommendations contribute to solving the buyer’s tasks, namely helping to complete the order |
| Logical Clarity | The buyer needs to see that the recommendations fulfil the task of completing the order. |
| Coverage | Recommendations should be for all products, including new and unpopular ones. |
| Context awareness | Recommendations for each product are based on information related to that product, making them more appropriate for that product. |
| Reach | Recommendations offer a variety of products that characterise the largest part of the online shop’s range of products. |
| Actuality | Recommendations take into account the changing product base and customer behaviour over time |
| Multiregional Support | Recommendations take into account the availability of products and the relevance of their attributes depending on the region |
We list the components of the related goods algorithm and the properties they provide. A single property may be provided by multiple components, as some components may work better in different situations.
Components of the related products algorithm
Next, let’s list the 15 components of the algorithm and consider the non-obvious details of their operation. We have named each component according to the task it is intended for. It is worth noting that some components are primarily suitable for certain segments of online stores.
For each component we will tell you:
- what problem it is needed to solve;
- how we solve the problem in our algorithm;
- how to determine if there is a problem in the recommendation system;
- what properties the component provides.
Real-time personalization
Personalization allows the algorithm to show each shopper the recommendations that are best for them. The Related Products algorithm is used in the product card and on the cart page, so it must first take into account what products it offers recommendations for. But it’s also important to consider the shopper’s preferences, which need to be determined in real time based on their past actions.
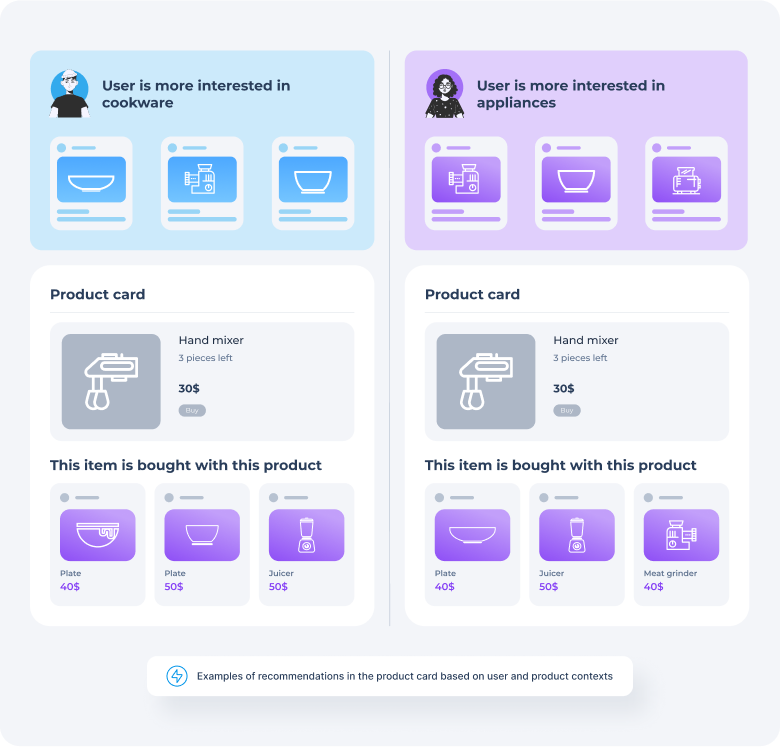
In order to form more accurate recommendations in the context of the current product, it is most useful to see what attributes of other products the customer was interested in.
For example, if the customer is on the product page “cat litter”, it is better to recommend cat food from the manufacturer in which the customer has previously shown interest.
At the same time, it is necessary to choose the right attributes for personalization. It would be a mistake to consider interest in every attribute or every value of an attribute. For example, interests in brands that customers rarely pay attention to should not be taken into account in personalization. Moreover, it happens that in one category an attribute should be taken into account, but in another category it is not.
To test the component it is enough to go to the product card with recommendations, and then perform some actions on the store’s site: visit the pages of other products or add them to the cart. After returning to the original product page, the recommendations should change.

The component provides the following properties:
- context awareness – using the buyer’s context for personalization allows to strengthen the property;
- task-oriented effectiveness – personalization helps the recommendations to match the buyer’s current task and therefore increases their effectiveness;
- coverage – personalization allows different products to be shown to different buyers for the same product;
- multiregional support – personalization should take into account the differences in attributes in different regions, e.g. prices.
Reducing the impact of popular items
Items bought together in an order either complement each other or are in the order independently of each other. The more popular a product is, the more often it is ordered and the more likely it is to be included in the order with the current product, even if it does not complement it. As a result, recommendations may include products that do not complement the current product. Therefore, the influence of popular products should be limited.
A simple way to limit the influence of popular products is to reduce the likelihood of a product being included in recommendations if it is purchased with other products. For example, a household goods store may show paper napkins and toilet paper in addition to laundry detergent instead of other laundry products. If the algorithm takes into account that paper napkins and toilet paper are also often purchased with other products, these products will most likely not appear in the recommendations for laundry detergent.
If you don’t limit the influence of popular products, they will start to appear in recommendations everywhere. Popular products influence the recommendations of every store, but it is easier to detect this influence on stores with super-popular products. It is enough to check a small number of recommendations and find the same products in the recommendations for different products in the card or in the cart.
The component provides the following properties:
- Logical Clarity – the probability of popular products that do not complement the current product being included in the recommendations is reduced;
- Reach – the display of the same popular products in recommendations is limited.
The solution to the “Banana Problem”
The problem of the influence of popular goods is most noticeable in grocery shops. In this regard, a separate term has emerged – the “Banana Problem”. Bananas are bought very often and with any other product, so they are present in recommendations for almost everything.
To solve this problem, a separate variant of the “Related Products” algorithm is used, which additionally reduces the influence of super-popular products. This option is not suitable for everyone and is intended primarily for shops with food, children’s goods and personal care products.
To test the work of the component, it is enough to check a small number of recommendations and find super-popular products in the recommendations for different products in the card or in the basket.
The component provides the following properties:
- logical clarity- it removes super popular products from the recommendations, which may not complement the current product.
Solving the problem of cold start
If a product has enough behavioural statistics, it is clear how to get related products – it is enough to use data on products in joint orders. But new products are constantly appearing in the shop, for which there is either no or little data. In addition, many online shops have a huge product base, and for a noticeable part of the goods data will not be much.
Weaker data sources than orders, such as shared product views and overall popularity, can be used to solve the problem. But naive use of such events will lead to the fact that the recommendations include products that may violate the logical clarity. As a consequence, the algorithm will become worse at solving the buyer’s tasks for which it is designed, and thus the task-oriented effectiveness will suffer.
In order to avoid this, our system automatically determines which categories can complement the current product. If a category is not suitable as a complementary category, then products from this category are not shown in the cold start.
You can evaluate the performance of this component by checking for recommendations for new or unpopular products.
Instead of this component you can show random products. But in this case you will have to sacrifice logic. It is necessary to make sure that the goods from the recommendations can be added to the current product.
To solve the problem of a cold start, you can show popular products. In this case, the same recommendations will be shown for different products, and, as a result, the properties of coverage and specificity will suffer.
The component provides the following properties:
- coverage – recommendations are generated for goods without statistics.
Brand prioritisation of the current product in a cold start
A cold start can offer a large variety of products, and it is important to select the most relevant ones from all this variety. For example, if a shop has a new laptop and there isn’t enough data on it yet, a cold start may suggest incompatible products.
For shop shoppers, brand is important, so prioritising by brand helps to highlight relevant products. It is important to note that if there is enough statistics, brand prioritisation can prevent the algorithm from finding relevant products. Therefore, this mechanism makes sense to use only in a cold start.
The problem solved by this variant of the algorithm can be found in recommendations to brands that produce both the main product and related products to it. For example, to see if apple accessories will be in the recommendations for a new macbook.
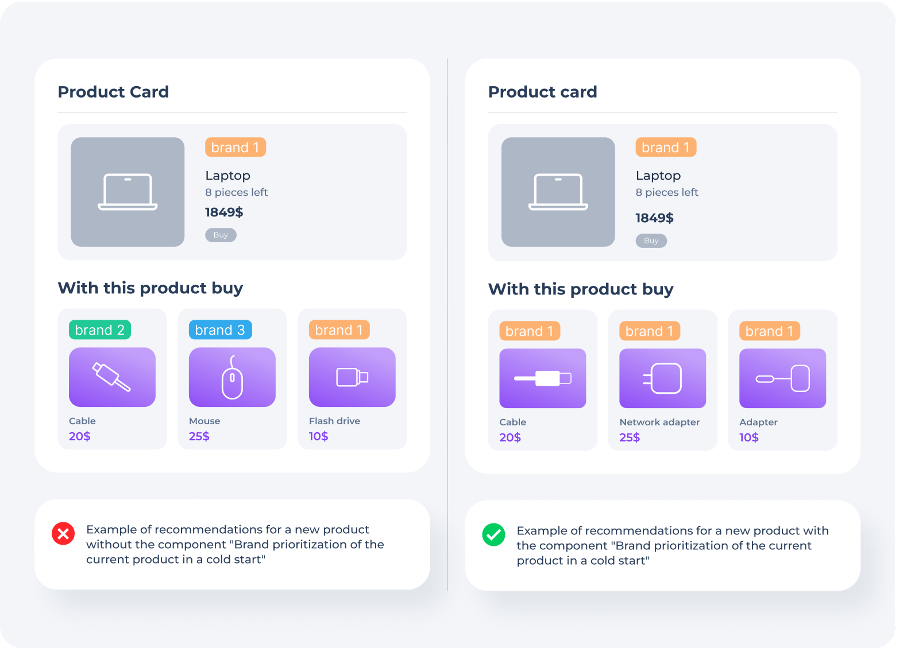
The component provides the following properties:
- task-oriented effectiveness – goods of the same brand are more likely to be combined with each other;
- context awareness – the brand of the current product is taken into account.
Cold start from current brand goods
In some segments, customers are strongly tied to specific brands, for example, in electronics and clothing. Therefore, there is no point in showing them products from another brand unless it is supported by sufficient data.
In such cases, you can form a cold start with only products from the current brand. In order to maintain coverage, you can show products of the same brand even if they are not found in joint events or are not popular.
The component provides the following properties:
- task-oriented effectiveness– the recommendations show goods of the brand that the customer likes;
- context awareness – the brand of the current product is taken into account.
Filtering of random products from illogical categories
Related products are primarily built by joint orders, which are the most important data source for this algorithm. In this case, an order may include products that do not complement each other, but were bought for some other reason. As a result, inappropriate products are shown in the recommendations.
In order to avoid random products in the recommendations, our system automatically determines which categories are suitable as related products. And the less a category fits as a related category, the more co-occurrences a product in that category needs to have in order to be included in recommendations. This is similar to how, in normal life, a person would need more evidence to agree with something they were initially unsure about.
As a check, you can look at different product cards and make sure that there are no illogical products among the recommendations. The majority of products may be logical, but there will be some products that do not complement the current product.

The component provides the following properties:
- logical clarity – the probability of showing inappropriate products is reduced;
- task-oriented effectiveness – more useful products are displayed in the recommendations.
Increase the variety of products in recommendations
Sometimes product recommendations can consist of many similar products. For example, a vacuum cleaner may be recommended with many bags that differ only in the number of bags in the set. In this case, the bags will fill the block with recommendations, and we will not help the buyer to solve his problem, for example, if he needs a filter for vacuum cleaner or bags of another type.
To solve this problem, it is necessary to be diversified recommendations, while not worsening the effectiveness of recommendations, i.e. do not let the products that complement the current product disappear from the rendition. For example, if there are similar products in the recommendations, but they are more effective relative to other products as related, they should be left.
This can be realized by a greedy algorithm that selects the most appropriate product from a set of related products, and then adds to it in the output of the next product that is the most appropriate, but taking into account the similarity in attributes with the previously selected products. This process is repeated until a sufficient number of items are selected.
The problem that the component solves is common. It manifests itself most clearly when you can get accurate recommendations, that is, first of all, in recommendations for popular products for which a lot of data is available. It is necessary to make sure that recommendations for such products do not consist mainly of very similar products.
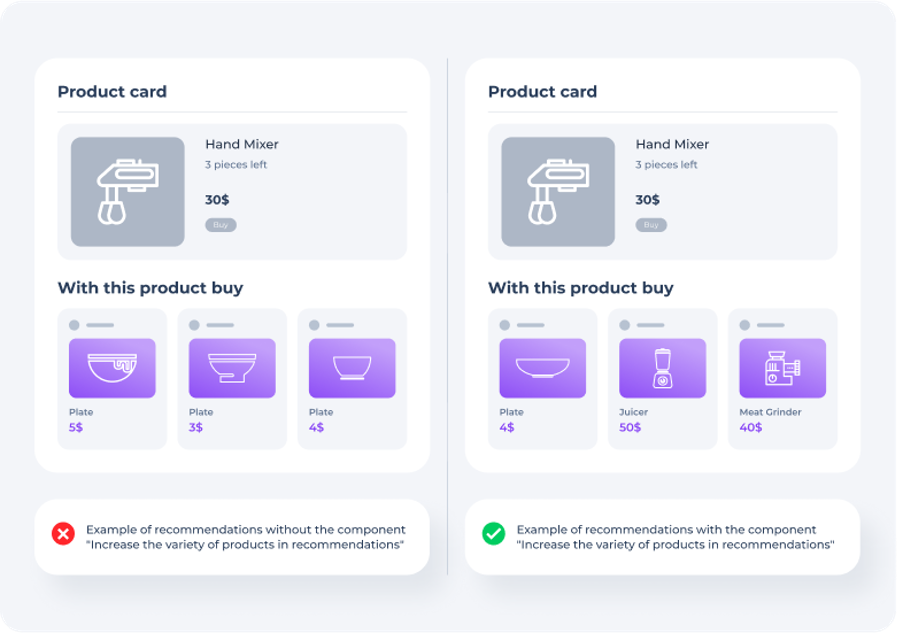
The component provides the following properties:
- task-oriented effectiveness – increases the probability of meeting the desired product among the recommended ones;
- reach – we show more different products.
Manual customization of recommendations
No matter how good the system is, in real life there are still products in recommendations that should not be there. These may be rare cases, and they will not significantly affect the effectiveness of recommendations, but they will be paid attention to. Therefore, such cases will be difficult to ignore.
In addition, there may be external factors that require certain restrictions in the algorithm. For example, a store needs to recommend alcohol only to alcohol and nothing else. In such a case, you need to be able to restrict the display of alcohol on other product pages.
To solve such cases, you can give the ability to add rules that allow or disallow recommending a certain group of products in specified contexts.
There are also many cases when it is necessary to show a certain group of goods under certain conditions, for example, in order to promote them. This is not the task of the recommendation algorithm, and we have put it into a separate product – Smart Placement Ads.
The component provides the following properties:
- logical clarity – the products that should not have been included but were included in the recommendations are filtered.
Exclusion of product categories for which recommendations are generated
Customers can order products from one category, while buying only one product and rejecting the others. This leads to the fact that the algorithm’s recommendations include products from the same category. At the same time, they will not necessarily be similar to each other. For example, people take several pairs of different jeans and buy only the one that fits better.
A simple solution is to exclude products from the current category from the recommendations. As a result, there will be no other jeans in the related products to the jeans.
This will allow the algorithm instead of jeans to show other products that will complement the current product, which is the task of the algorithm of related products.
And the task of finding alternative goods is solved by another algorithm.
To test it, we need to look, for example, in the clothing segment, 20-30 goods. In the absence of the component, it will be possible to see in the recommendations the goods from the current category.
The component provides the following properties:
- logical clarity – goods that are not related to the algorithm’s task are excluded;
- task-oriented effectiveness – goods that help to solve the buyer’s task remain.
Calculation of recommendations for each product of the group
In some stores, there are many variations of a single item that make up a group. Products of one group may differ, for example, in size, color or availability. At the same time, there can be dozens of products in a group. And out of this set, only one product should be shown in the recommendations for the current product.
It is possible to represent the whole group as one product and calculate general statistics for all products of the group. In this case it will not be possible to find the most appropriate for the current product from the set of goods of the group.
As a solution to the problem, we separately consider the events for each commodity of the group. In this way, we learn that a particular item in the group best complements the current item. But in this case, the already large number of items in the recommendation calculation may increase by an order of magnitude, which will require more computing power.
To check the availability of the component you need to add a specific product of the group to the cart on the store with group goods and make sure that the recommendations show the most suitable products of other groups, for example, green shoes are recommended to a green bag.
The component provides the following properties:
- task-oriented effectiveness – the most appropriate product from the group is shown;
- context awareness – the context of a particular product of the group is taken into account.
Calculation of recommendations for each region
Goods can be linked to different locations such as stores, warehouses, regions, etc. For simplicity, we will call such places regions. There can be a large number of them in a store – hundreds and sometimes even thousands. Besides, there can be hundreds of thousands of goods in the store. In each region, the goods may differ in attributes and availability. And for each region it is necessary to show relevant and up-to-date recommendations.
Availability in each region may vary, and it is important to show only those products that are available to customers in their region. In addition, it is important to use the attributes of products that are relevant to the region, primarily the price. It should be noted that you can not just take recommendations for all regions and leave the available goods for the current region, because in small regions because of the small available product base after filtering the goods will not remain. Or there may be a lot of similar ones left, which will violate the diversity of goods in the recommendations. So, recommendations for each region should be formed separately.
In addition, product attributes are used in personalization and it is important to consider attribute values relevant to the current region.
To check the availability of a component, you can open a small region in the store, view a group of products and make sure that there are recommendations with no out-of-stock items among them. To check the relevance of prices, you can select two geographically distant regions, find products in recommendations that have different prices in the card in these regions, and then make sure that the prices in recommendations of these products are also different.
The component provides the following properties:
- task-oriented effectiveness – the most suitable products for the region are shown;
- logical clarity – recommendations are shown for each product in each region;
- reach – a sufficient number of different products are shown in the recommendations;
- multiregional support – the current status of products depending on the region is taken into account.
Using data for all available time
Most items in a store tend to be ordered relatively infrequently. This phenomenon is known as the “long tail.” If products have too few orders, it starts to negatively affect the quality of recommendations. It is therefore important to collect as much data as possible for low demand items.
In order to accumulate a lot of data for each commodity, we need to collect events over as much time as possible. At the same time, increasing the amount of data for low-demand items will also significantly increase the data for other items, which ultimately leads to an increase in the amount of computation.
We experimentally tested whether the amount of data used by the algorithm actually affects its performance. To do this, we compared recommendations based on several years of data with a variant that only considers the history of the last few months. As a result, we found that the more data the algorithm uses, the better it performs.
In order to get enough data right from the moment recommendations are installed on a store, it is important to be able to upload historical order data to the system so that it can be used to calculate recommendations.
To check it, it is necessary to find an unpopular product and compare the quality and quantity of recommendations for it with that shown for popular products.
The component provides the following properties:
- task-oriented effectiveness – more data on customer behavior is used;
- logical clarity – more data is available for more products.
Updating of recommendations
In every store, new products are constantly appearing, old products are out of stock, and various attributes of available products are changing. As a consequence, new products may be missing in recommendations, out-of-stock products, irrelevant attributes, first of all, prices. For example, if a product is no longer available, but is shown in recommendations or is shown with an irrelevant price – this can undermine the buyer’s confidence in the tool and in the store as a whole.
At the same time, the store may have a large number of products that form groups of many variants in a large number of regions. And recommendations for each product variant in each region need to be obtained and continually updated.
In addition, new data about the interaction of customers with products comes in, which leads to changes in their current popularity and which products currently best complement each other. All of this makes the task of calculating recommendations extremely computationally challenging.
Product data is transmitted to us in real time, which makes it possible to immediately apply changes related to the display of product attributes in recommendations, such as changing the price, availability of a promotion or discount. If a product becomes unavailable, it immediately disappears from the recommendations. At the same time, recommendations for unavailable products continue to be shown.
The algorithm of related products in real time is quite difficult to calculate, given the need to provide all the properties of quality recommendations. That’s why we process new products and new data on the interaction of buyers with products once a day. In addition, we upload more products for display than are required in the recommendations. So if some products go out of stock, there will still be enough products left in the recommendations. Also, uploading a large number of candidates is necessary for the personalization component to select the most appropriate products in real time.
To verify that new items are processed in a timely manner, you can make sure that there are recommendations for them. It is expected that if new items are not in the system, there will be no recommendations for them.
To identify the problem with unavailable products or product data relevance, you can find in the recommendations the products with the most active demand at the moment, which are actively bought and may run out or change the price. Examples would be seasonal and promotional items. You should make sure that there are no out-of-stock items in the recommendations and that the prices of all items are up-to-date.

The component provides the following properties:
- logical clarity – recommendations are changed in a timely manner;
- task-oriented effectiveness – up-to-date data is used;
- coverage – recommendations for new products are shown.
Filtering of extreme statistics
Along with correct data about customer behavior, the recommendation system will receive anomalous data. For example, a single customer may buy an extremely large number of items in one or multiple orders. This can happen due to a mistake, test orders, or because the buyer’s behavior is very different from the others.
A small number of anomalous users can greatly affect recommendations. For example, a buyer may place many orders with items that would not normally be placed together in an order and the system will consider them to be complementary.
In addition, data from anomalous users can complicate the algorithm’s calculation, since all pairs of items in an order must be considered. The number of pairs is much larger than the number of products themselves. For example, in an order of 100 different products, the algorithm needs to consider 100*99/2 = 4950 pairs.
As a solution, we remove a small fraction of customers who make an abnormal number of events from the data to compute the algorithm. In this way, the probability of using unrepresentative behavior in recommendations is reduced, while still having enough correct data to compute recommendations.
If, despite the fact that all other components are working correctly, you observe illogical products in recommendations, then as a result of a detailed investigation of the problem, you are likely to find an anomaly in the data.
The component provides the following properties:
- logical clarity– statistics that distort recommendations are filtered.
Conclusion
In this paper, we have used the example of the Related Products algorithm to show how to provide the necessary properties of quality recommendations. Properly selected and implemented components allow to find a compromise between properties, the joint fulfillment of which is a complex task.
Without the components considered, the algorithm will not provide all the necessary properties, and thus problems will arise that will need to be solved at some point. The choice of components may depend on the particular market segment. For example, the component for the “banana problem” is primarily needed by grocery, baby, and pet stores, but most of the components are important for any store.
In the next article, we will look at interesting features of other algorithms that allow us to provide the necessary properties of quality recommendations.